About Me

Data Scientist with 2+ years of experience shipping ML models, data pipelines, and analytics solutions that drive real business impact. At Paisabazaar (India's largest credit marketplace), I built XGBoost and CatBoost models on 500K+ samples that increased customer acquisition by 28% and reduced loan defaults by 32%, and helped scale a financial product from $1.2M to $11M in 3 months. I've processed 30M+ daily records, built PySpark data marts, and deployed end-to-end ML systems on AWS ECS Fargate. MS in Business Analytics from Northeastern University (GPA 3.8).
Skills
Languages






Data manipulation, scripting, and database querying
Frameworks & Libraries








Machine learning, deep learning, and AI frameworks
BI & Visualization






Interactive dashboards, KPI tracking, and data storytelling
Tools







Version control, IDEs, and development environments
Cloud & Data







Cloud infrastructure, data warehousing, and ETL pipelines
Education & Experience
For more information, have a look at my curriculum vitae .
-
September 2024 - December 2025
 Graduate Teaching AssistantPython SQL R Gemini Claude BigQuery Snowflake
Graduate Teaching AssistantPython SQL R Gemini Claude BigQuery Snowflake -
June 2025 - August 2025
Analytics Consultant InternBoard ERP FP&A Data Modeling ETL
-
September 2024 - December 2025
M.S. Business Analytics (GPA 3.8)
-
March 2024 - June 2024
 Data EngineerPython AWS PostgreSQL MongoDB Tableau Selenium
Data EngineerPython AWS PostgreSQL MongoDB Tableau Selenium -
August 2022 - August 2023
 PG Diploma Computer Science
PG Diploma Computer Science -
February 2022 - March 2024
 Data ScientistPython XGBoost CatBoost PySpark Hive Power BI
Data ScientistPython XGBoost CatBoost PySpark Hive Power BI -
July 2018 - July 2021
 B.Sc. Physics
B.Sc. Physics
Projects

Healthcare Fraud Detection
End-to-end ML pipeline for Medicare fraud detection across 5,400+ providers. Engineered 44 predictive features, Optuna hyperparameter tuning, FastAPI + Gradio UI, and CI/CD to AWS ECS Fargate.

NYC Taxi Data Pipeline
Ingested 20M+ taxi trip records into GCS and BigQuery. Provisioned GCP infrastructure with Terraform, built 10+ Kestra workflow orchestrations, and developed dbt models for analytics-ready schemas.

Insurance Cross-Sell Prediction
LightGBM classification model on 380K customer records with SMOTE for class imbalance. Applied SHAP for model interpretation, identifying key predictors of purchase intent.
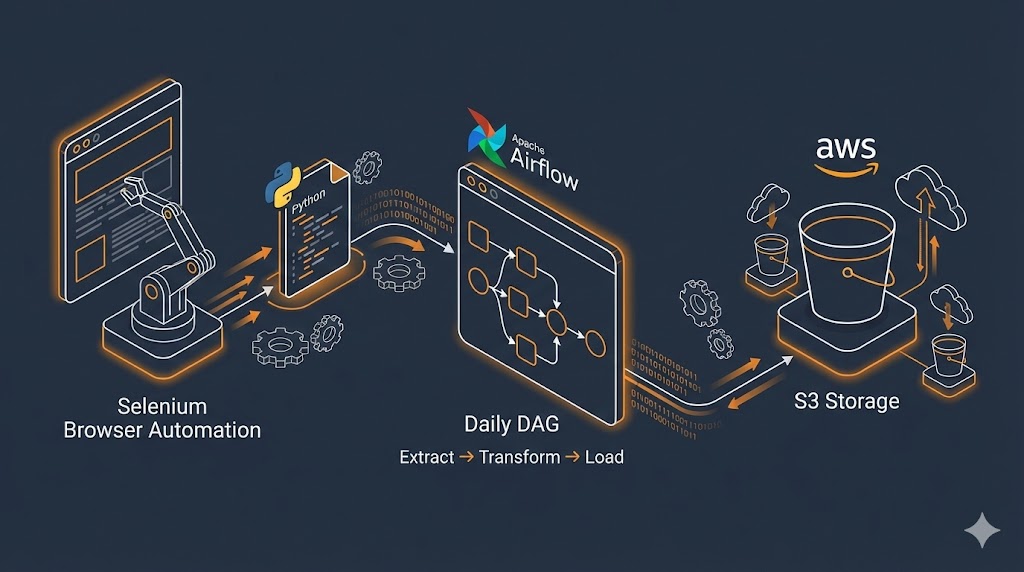
ETL Pipeline Orchestration
Scalable ETL pipeline using Selenium + Pandas, storing 1000+ daily records in AWS S3. Automated with Airflow DAGs on EC2 with error handling and retry logic.
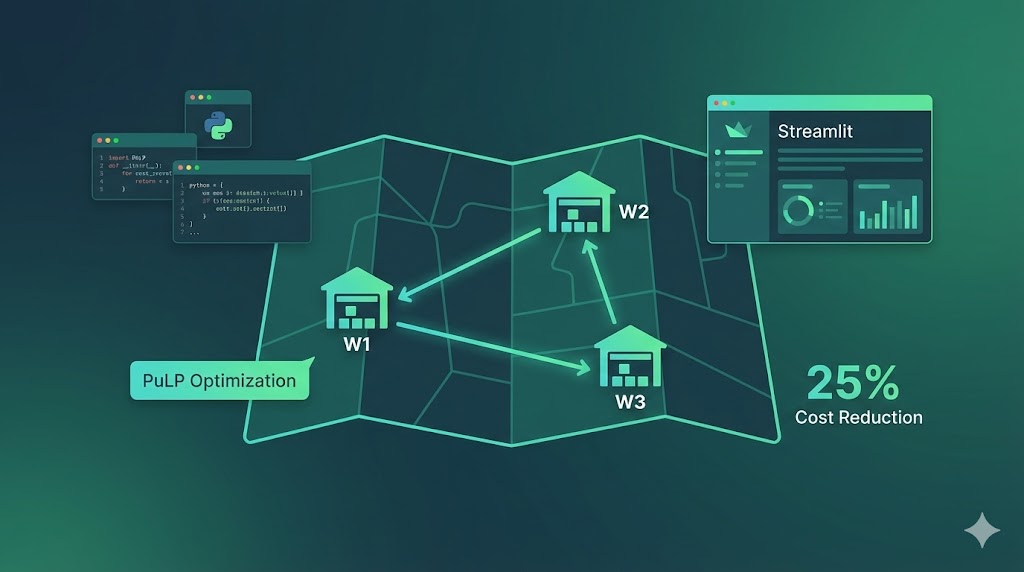
Supply Chain Optimization
Linear programming model using PuLP to optimize shipping across a 3-warehouse network. Interactive Streamlit dashboard with what-if analysis for scenario planning.
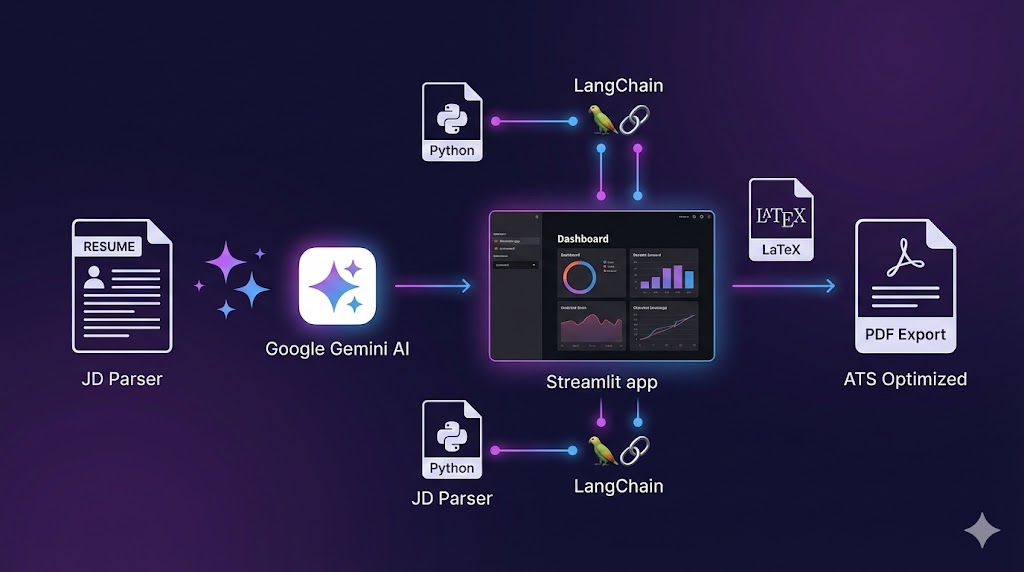
Resume Tailoring Automation
Automated resume customization using Gemini API with keyword extraction and ATS optimization. End-to-end pipeline from JD parsing to PDF generation via LaTeX.

Movie Recommendation System
Content-based engine using KNN with cosine similarity on sparse feature vectors from 3000+ movies. Dockerized Streamlit app with CI/CD via GitHub Actions and TMDB API integration.
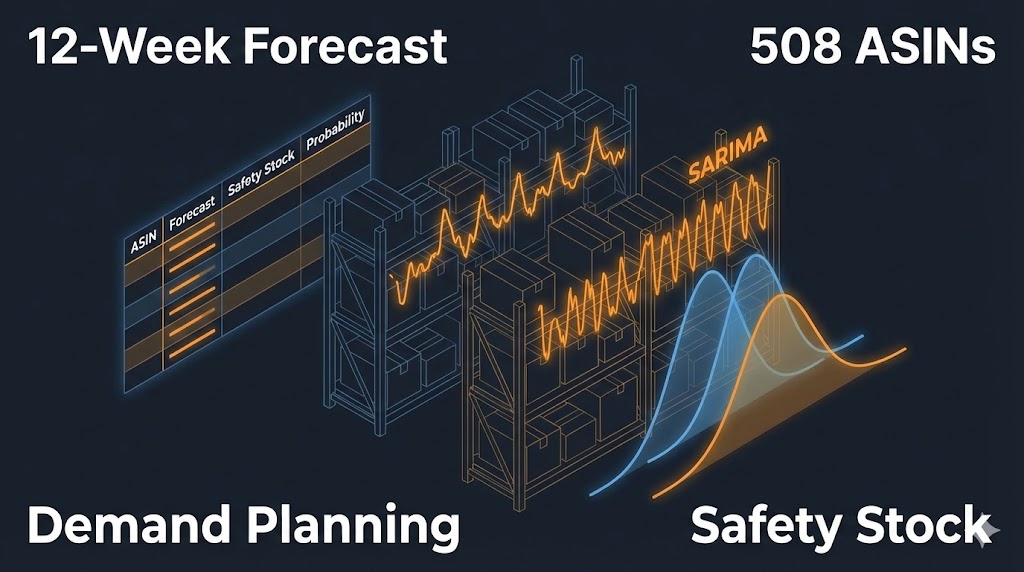
Inventory Optimization Forecasting
12-week purchase order forecasting model for retail using ensemble SARIMA and Monte Carlo simulation. Risk-based reorder points across 508 ASINs with statistical validation.
Contact
MS Business Analytics from Northeastern (GPA 3.8) with 2+ years at Paisabazaar building ML models on 500K+ samples and scaling products to $11M. Actively seeking Data Scientist, ML Engineer, and Business Analyst roles. Based in Boston, MA - open to relocation.